Riftsaw supports short-lived and long-running process executions, process persistence and recovery, process versioning, JBoss deployment architecture enabling hot deployment of your BPEL processes and integration with JBossESB and UDDI using jUDDI. An Eclipse-based BPEL designer is bundled with JBossTools 3.1.
Riftsaw is based on Apache Ode, and adds support to run on any JAX-WS compliant WebServices stack and it ships with a new GWT based Admin console.
From BPEL to the ESB and Back - Introduction to the Riftsaw-JBoss ESB Integration
Friday, December 18, 2009
jBPM goes BPMN!
http://www.jorambarrez.be/blog/2009/12/04/jbpm-goes-bpmn/
What is BPMN2?
Basically, the Business Process Modeling Notation (BPMN) started out a pure graphical notation standard for business processes, maintained by the Object Management Group (OMG). Version 2.0, which currently is in beta, adds execution semantics to the specification and this is of course where it gets interesting for jBPM.
The primary benefit of BPMN2 is that it is a standard accepted by the IT industry, which means that process models become portable (graphical and execution-wise) across process engines such as jBPM. Since process executions are the raison-d-être of jBPM, it is only natural we are now investing in BPMN2. People who are familiar with JPDL (the current native language of jBPM) will have generally no difficulties in learning the BPMN2 language, as many constructs and concepts are shared. In fact, from a high-level point of view, BPMN2 and JPDL are in concept solving the same problem
What is BPMN2?
Basically, the Business Process Modeling Notation (BPMN) started out a pure graphical notation standard for business processes, maintained by the Object Management Group (OMG). Version 2.0, which currently is in beta, adds execution semantics to the specification and this is of course where it gets interesting for jBPM.
The primary benefit of BPMN2 is that it is a standard accepted by the IT industry, which means that process models become portable (graphical and execution-wise) across process engines such as jBPM. Since process executions are the raison-d-être of jBPM, it is only natural we are now investing in BPMN2. People who are familiar with JPDL (the current native language of jBPM) will have generally no difficulties in learning the BPMN2 language, as many constructs and concepts are shared. In fact, from a high-level point of view, BPMN2 and JPDL are in concept solving the same problem
What is different jBPM and Riftsaw?
Riftsaw is based up-on Apache ODE and there is no BPEL engine available on top of the PVM(Process Virtual Machine). There is no BPEL in jBPM4 anymore. There is just jPDL and BPMN2 which is still in development.
jBPM3 BPEL is a BPEL 1.x implementation while Riftsaw is a BPEL 2.0 implementation.
jBPM3 BPEL is a BPEL 1.x implementation while Riftsaw is a BPEL 2.0 implementation.
SCA Spring in Weblogic 10.3.2 & Soa Suite 11g
Are you ready for SCA? Currently, the SCA is much more popular. The follow links are a introduction of SCA Spring on WebLogic 10g.
SCA Spring in Weblogic 10.3.2 & Soa Suite 11g
SCA Spring in Weblogic 10.3.2 & Soa Suite 11g Part 2
SCA Spring in Weblogic 10.3.2 & Soa Suite 11g
SCA Spring in Weblogic 10.3.2 & Soa Suite 11g Part 2
Friday, December 11, 2009
Java Persistence API Pro
(From http://hobione.wordpress.com/jpapro/)
Chapter 4
Java Persistence API Pro
Book Reference: Pro EJB 3: Java Persistence API (Pro)
Chapter 1
Why Persistence?
As all we know that understanding the relational data is key to successful enterprise development. Moving data back and forth between to database system and the object model of a Java application is a lot harder than it needs to be. Java developers either seem to spend a lot of time converting row and column data into objects, or they find themselves tied to proprietary frameworks that try to hide the database from the developer. The Java Persistence API is set to have a major impact on the way we handle persistence within Java. For the first time, developers have a standard way of bridging the gap between object-oriented domain models and relational database systems.
Java Object – Database Relational Mapping:
The main thought behind to convert JDBC result sets into something object-oriented as follows.
” The domain model has a class. The database has a table. They look pretty similar. It should be simple to convert from one to the other automatically” The science of bridging gap between the object model and the relational model is known as object-relational mapping, aka O-R mapping or ORM.
Inheritance (Life is a dirty beach without JPA):
A defining element of an object-oriented domain model is to opportunity to introduce generalized relationships between like classes. Inheritance is the natural way to express these relationship and allows for polymorphisms in the application. When a developer start to consider abstract superclasses or parent classes with no persistent form, inheritance rapidly becomes a complex issue in object-relational mapping. Not only is there a challenge with storage of the class data, but the complex table realtionship are difficult to query efficiently.
JPA saves our soul (SOS):
The Java Persistence API is a lightweight, POJO-based framework for Java persistence. Although object-relational mapping is a major component of the API, it also offers solutions to the architectural challenges of integrating persistence into scalable enterprise applications.
Overview: JPA = Simple + elegant + powerful + flexible
Natural to use and easy to learn.
POJO: It means there is nothing special about any object that is made persistent. Java Persistence API is entirely metadata driven and it can be done by adding annotations to the code or using externally defined XML.
Non-Intrusiveness: The persistence API exists as a separate layer from persistence objects. The application must be aware of the persistence API, the persistence objects themselves need not be aware.
Object Queries: Query Language that derived from EJB QL and modeled after SQL for its familiarity, but it is not tied to the database schema. Queries use a schema abstraction that is based on the state of an entity as opposed to the columns in which the entity is stored. It returns results that are in the form of entities that enable querying across the Java domain model instead of across database tables.
Mobile Entities:
Simple Configuration:
Integration and Testability:
Chapter 2
Entity Overview: The entity is not a new thing. In fact, entities have been around longer than many programming languages and certainly longer than Java. Peter Chen who first introduced entity-relational modeling (1976) described entities as things that have attributes and relationships.
Here is an example of an Entity class from a regular Java Class:
package examples.model;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Employee {
@Id
private int id;
private String name;
private long salary;
public Employee() {}
public Employee(int id) {
this.id = id;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getSalary() {
return salary;
}
public void setSalary(long salary) {
this.salary = salary;
}
public String toString() {
return "Employee id: " + getId() + " name: " + getName() + " salary: " + getSalary();
}
}
To turn Employee into an entity we first needed to annotate the class with @Entity. This is primarily just a marker annotation to indicate to the persistence engine that the class is an entity. The second annotation was needed to use as the unique identifying key in the table. All entities of type Employee will get stored in a table called EMPLOYEE.
Entity Manager: Until an entity manager is used to actually create, read or write an entity, the entity is nothing more than a regular (non-persistent) Java object. An entity manager is the show for the game. The set of managed entity instances within an entity instances withing an entity manager at any given time is called it’s persistence context. Only one Java instance with the same persistent identity may exist in a persistence context any any time. For example, if an Employee with a persistent identity (or id) of 158 exists in the persistence context, then no other object with its id set to 158 may exist within that same persistence context. All entity managers come from factories of type EntityManagerFactory. For Java SE application should use EntityTransaction instead of Entity Manager.
Obtaining an Entity Manger: The static createEntityMangerFactory() method creates EntityManagerFactory from persistence unit name “EmployeeServices”:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("EmployeeService");
Now we have a factory, we can obtain an entity manager from it:
EntityManager em = emf.createEntityManager();
Persisting an Entity: Insert. It creates a new employee and persist it to the database table
public Employee createEmployee(int id, String name, long salary) {
Employee emp = new Employee(id);
emp.setName(name);
emp.setSalary(salary);
em.persist(emp);
return emp;
}
Finding an Entity: Read
public Employee findEmployee(int id) {
return em.find(Employee.class, id);
}
In this case where no employee exists for the id that is passed in, when the method will return null, since that is what find() will return.
Removing and Entity: Delete
public void removeEmployee(int id) {
Employee emp = findEmployee(id);
if (emp != null) {
em.remove(emp);
}
}
Updating an Entity: Update
public Employee raiseEmployeeSalary(int id, long raise) {
Employee emp = em.find(Employee.class, id);
if (emp != null) {
emp.setSalary(emp.getSalary() + raise);
}
return emp;
}
Queries: Instead of using Structured Query Language (SQL) to specify the query criteria, in persistence world, we query over entities and using a language called Java Persistence Query Language (JPQL).
A query is implemented in code as a Query object and it constructed using EntityManger as a factory.
As a first class object, this query can in turn be customized according to the needs of the application.
A query can be defined either statically or dynamically (more expensive to execute). Also there is kind of query called named query as well.
public Collection<Employee> findAllEmployees() {
Query query = em.createQuery("SELECT e FROM Employee e");
return ( Collection <Employee> ) query.getResultList();
}
To execute the query, simply invoke getResultList() on it and this returns a List. Note that a List <Employee> is not returned b/c no class is passed into the call, so no parameterization of the type is able to occur. The return type is indirect by the persistence provider as it processes the JPQL String. By doing this ( Collection<Employee> ) to make a neater return type.
Chapter 3
EJB definitions:
Chapter 4
Object-Relational Mapping
Lazy Fetching: The data to be fetched only when or if it is required is called lazy loading, deferred loading, lazy fetching, on-demand fetching, jun-in-time reading, indirection. Data may not be loaded when the object is initially read from the database but will be fetched only when it is referenced or accessed. The FetchType could be LAZY or EAGER. Lazy = until it is referenced. The default is to eagerly load all basic mappings.
package examples.model;
import static javax.persistence.FetchType.LAZY;
import javax.persistence.Basic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Lob;
@Entity
public class Employee {
@Id
private int id;
private String name;
private long salary;
@Basic(fetch=LAZY)
@Lob @Column( name = "PIC" )
private byte[] picture;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
......
@Basic annotation is required. The comments field to be fetched lazily will allow an Employee instance returned from a query to have the comment field empty. It will be transparently read and filled in by the provider (Toplink/Hibernate) once the comments filed get accessed.
Two things to be aware of.
First and foremost: The directive to lazily fetch an attribute is meant only to be a hint to the persistence provider to help the application achieve better performance. The provider is not required to respect the request, since the behavior of the entity is not compromised if the provider goes ahead and loads the attribute.
Second: It may appear that this is a good idea for certain attributes but it is almost never a good idea to lazily fetch for simple types. The only time when lazy loading of a basic mapping should be considered are when either there are many columns in a table (for example, dozens or hundreds) or when the columns are large (for example, very large character strings or byte strings).
Large Object:
Using jQuery with Other Libraries
The jQuery library, and virtually all of its plugins are constrained within the jQuery namespace. As a general rule, "global" objects are stored inside the jQuery namespace as well, so you shouldn't get a clash between jQuery and any other library (like Prototype, MooTools, or YUI).
That said, there is one caveat: By default, jQuery uses "$" as a shortcut for "jQuery".
However, you can override that default by calling jQuery.noConflict() at any point after jQuery and the other library have both loaded.
When you use jQuery with other libraries, jQuery still is functional.
You can use jQuery directly
or reassign jQuery to another shortcut
For more detail, please see http://docs.jquery.com/Using_jQuery_with_Other_Libraries.
That said, there is one caveat: By default, jQuery uses "$" as a shortcut for "jQuery".
However, you can override that default by calling jQuery.noConflict() at any point after jQuery and the other library have both loaded.
When you use jQuery with other libraries, jQuery still is functional.
You can use jQuery directly
// Use jQuery via jQuery(...)
jQuery(document).ready(function(){
jQuery("div").hide();
});
or reassign jQuery to another shortcut
var $j = jQuery;
// Use jQuery via $j(...)
$j(document).ready(function(){
$j("div").hide();
});
For more detail, please see http://docs.jquery.com/Using_jQuery_with_Other_Libraries.
Thursday, December 10, 2009
Why use Map.entrySet() instead of Map.keySet()?
(From http://www.coderanch.com/t/382487/Java-General/java/Why-use-Map-entrySet)
If you just need keys, use keySet(). If you just need values, use values(). If you're going to use keys and values in your subsequent code, then you're best off using entrySet().
I frequently see people do this without entrySet(), and it usually looks something like this:
This works, but it's making the JVM do extra work for no good reason. Every time you call get() you're making the JVM spend time doing a hashcode lookup, or navigating a tree and evaluating a comparator. These operations may be fast, or not, but why do them if you don't have to? A Map.Entry gives you both key and value, together, in the most efficient manner possible.
Under JDK 5 and later it's a little nicer:
If you just need keys, use keySet(). If you just need values, use values(). If you're going to use keys and values in your subsequent code, then you're best off using entrySet().
I frequently see people do this without entrySet(), and it usually looks something like this:
for (Iterator it = map.keySet().iterator(); it.hasNext(); ) {
Foo key = (Foo) it.next();
Bar value = (Bar) map.get(key);
// now do something with key and value
}
This works, but it's making the JVM do extra work for no good reason. Every time you call get() you're making the JVM spend time doing a hashcode lookup, or navigating a tree and evaluating a comparator. These operations may be fast, or not, but why do them if you don't have to? A Map.Entry gives you both key and value, together, in the most efficient manner possible.
for (Iterator it = map.entrySet().iterator(); it.hasNext(); ) {
Map.Entry e = (Map.Entry) it.next();
Foo key = (Foo) e.getKey();
Bar value = (Bar) e.getValue();
// now do something with key and value
}
Under JDK 5 and later it's a little nicer:
for (Map.Entry e : map.entrySet()) {
Foo key = e.getKey();
Bar value = e.getValue();
// now do something with key and value
}
Thursday, December 03, 2009
Import a certificate to keystore.
Import a certificate into default key store 'cacerts'.
keytool -import -trustcacerts -keystore cacerts -alias drssomp0117 -file drss117.2048.crt
keytool -import -trustcacerts -keystore cacerts -alias drssomp0117 -file drss117.2048.crt
Wednesday, December 02, 2009
Java JDK 1.4 JCE Provider issue.
Bundled JCE provider in jdk1.4 can't cope with keys bigger than 2048. If you are working on a websrvice, which needs using https to access, you maybe will be in trouble as commocial certificates most need 4096. In Java 1.5 and higher, it is OK as longer key was supported as default. How to sovle this issue? You have to find an alternative JCE provider that supports key size 4096.
Provider resources:
http://www.bouncycastle.org/java.html
http://www.cryptix.org/
Provider resources:
http://www.bouncycastle.org/java.html
http://www.cryptix.org/
Wednesday, November 25, 2009
What's New in WSDL 2.0
WSDL 1.2 was renamed WSDL 2.0 because of its substantial differences from WSDL 1.1. Some of these changes include:
.Adding further semantics to the description language. This is one of the reasons for making targetNamespace a required attribute of the definitions element in WSDL 2.0.
.Removal of message constructs. These are specified using the XML schema type system in the types element.
.No support for operator overloading.
.PortTypes renamed to interfaces. Support for interface inheritance is achieved by using the extends attribute in the interface element.
.Ports renamed to endpoints.
(From http://www.xml.com/pub/a/ws/2004/05/19/wsdl2.html)
.Adding further semantics to the description language. This is one of the reasons for making targetNamespace a required attribute of the definitions element in WSDL 2.0.
.Removal of message constructs. These are specified using the XML schema type system in the types element.
.No support for operator overloading.
.PortTypes renamed to interfaces. Support for interface inheritance is achieved by using the extends attribute in the interface element.
.Ports renamed to endpoints.
(From http://www.xml.com/pub/a/ws/2004/05/19/wsdl2.html)
Sunday, November 22, 2009
Getting Started with Java EE 6
Getting Started with Java EE 6
In this tutorial we’ll update you on the world of Java EE 6 with the help of a Twitter-like demo application we’ve code-named wallfriend. The demo application contains JSF 2.0, PrimeFaces, CDI and Weld as well as Hibernate Validator frameworks.
In this tutorial we’ll update you on the world of Java EE 6 with the help of a Twitter-like demo application we’ve code-named wallfriend. The demo application contains JSF 2.0, PrimeFaces, CDI and Weld as well as Hibernate Validator frameworks.
Wednesday, November 11, 2009
Keystore and Truststore Definitions
JSSE introduces the notion of a truststore, which is a database that holds certificates. In fact, a truststore has exactly the same format as a keystore; both are administered with keytool, and both are represented programmatically as instances of the KeyStore class. The difference between a keystore and a truststore is more a matter of function than of programming construct, as we will see.
The server in an SSL conversation must have a private key and a certificate that verifies its identity. The private key is used by the server as part of the key exchange algorithm, and the certificate is sent to the client to tell the client who the server is. This information is obtained from the keystore. Remember that the private key is never sent from the server to the client; it is used only as an input to the key exchange algorithm.
SSL servers can require that the client authenticate itself as well. In that case, the client must have its own keystore with a private key and certificate.
The truststore is used by the client to verify the certificate that is sent by the server. If I set up an SSL server, it will use a certificate from my keystore to vouch for my identity. This certificate is signed by a trusted certificate authority (or, as we've seen, there may be a chain of certificates, the last of which is signed by a recognized CA). When your SSL client receives my certificate, it must verify that certificate, which means that the trusted CA's certificate must be in your local truststore. In general, all SSL clients must have a truststore. If an SSL server requires client authentication, it must also have a truststore.
In sum, keystores are used to provide credentials, while truststores are used to verify credentials. Servers use keystores to obtain the certificates they present to the clients; clients use truststores to obtain root certificates in order to verify the servers' certificates.
The keystore and truststore can be (and often are) the same file. However, it's usually easier to manage keys if they are separate: the truststore can contain the public certificates of trusted CAs and can be shared easily, while the keystore can contain the private key and certificate of the local organization and can be stored in a protected location. In addition, JSSE is easier to use if the keystore contains a single alias. When the keystore contains multiple aliases there are ways to specify which one should be used, but that requires more programming. Keep in mind that in general a keystore containing a single alias makes using JSSE simpler.
A keystore contains private keys, and the certificates with their corresponding public keys. You only need this if you are a server, or if the server requires client authentication.
A truststore contains certificates from other parties that you expect to communicate with, or from Certificate Authorities that you trust to identify other parties. If your server’s certificate is signed by a recognized CA, the default truststore that ships with the JR will already trust it (because it already trusts trustworthy CAs), so you don’t need to build your own, or to add anything to the one from the JRE.
The server in an SSL conversation must have a private key and a certificate that verifies its identity. The private key is used by the server as part of the key exchange algorithm, and the certificate is sent to the client to tell the client who the server is. This information is obtained from the keystore. Remember that the private key is never sent from the server to the client; it is used only as an input to the key exchange algorithm.
SSL servers can require that the client authenticate itself as well. In that case, the client must have its own keystore with a private key and certificate.
The truststore is used by the client to verify the certificate that is sent by the server. If I set up an SSL server, it will use a certificate from my keystore to vouch for my identity. This certificate is signed by a trusted certificate authority (or, as we've seen, there may be a chain of certificates, the last of which is signed by a recognized CA). When your SSL client receives my certificate, it must verify that certificate, which means that the trusted CA's certificate must be in your local truststore. In general, all SSL clients must have a truststore. If an SSL server requires client authentication, it must also have a truststore.
In sum, keystores are used to provide credentials, while truststores are used to verify credentials. Servers use keystores to obtain the certificates they present to the clients; clients use truststores to obtain root certificates in order to verify the servers' certificates.
The keystore and truststore can be (and often are) the same file. However, it's usually easier to manage keys if they are separate: the truststore can contain the public certificates of trusted CAs and can be shared easily, while the keystore can contain the private key and certificate of the local organization and can be stored in a protected location. In addition, JSSE is easier to use if the keystore contains a single alias. When the keystore contains multiple aliases there are ways to specify which one should be used, but that requires more programming. Keep in mind that in general a keystore containing a single alias makes using JSSE simpler.
A keystore contains private keys, and the certificates with their corresponding public keys. You only need this if you are a server, or if the server requires client authentication.
A truststore contains certificates from other parties that you expect to communicate with, or from Certificate Authorities that you trust to identify other parties. If your server’s certificate is signed by a recognized CA, the default truststore that ships with the JR will already trust it (because it already trusts trustworthy CAs), so you don’t need to build your own, or to add anything to the one from the JRE.
keyStore vs trustStore
Basically they can be a single store or separate.
You will store in Keystore normally your private stuff and have a different store of trusted entries.
The separation is good idea.
The keystore will be used for encrypting/signing some thing with your private key while the trust stores will be used mostly to authenticate remote servers etc.
In java I think to trust any entries you will pass -trustcacerts option.
You always need a truststore that points to a file containing trusted certificates, no matter whether you are implementing the server or the client side of the protocol, with one exception. This file is often has a name like cacerts, and by default it may turn out to be a file named cacerts in your jre security directory. The filenames you gave are not defaults, so their contents are not obvious to me.
You may or may not need a keystore. The keystore points to a file containing private key material. You need a keystore if:
1) you are implementing the server side of the protocol, or
2) you are implementing the client side and you need to authenticate yourself to the server.
There is one exception to everything stated. If you are using certain anonymous DH ciphersuites, then neither side needs either a truststore or a keystore. The connection is unauthenticated.
You will store in Keystore normally your private stuff and have a different store of trusted entries.
The separation is good idea.
The keystore will be used for encrypting/signing some thing with your private key while the trust stores will be used mostly to authenticate remote servers etc.
In java I think to trust any entries you will pass -trustcacerts option.
You always need a truststore that points to a file containing trusted certificates, no matter whether you are implementing the server or the client side of the protocol, with one exception. This file is often has a name like cacerts, and by default it may turn out to be a file named cacerts in your jre security directory. The filenames you gave are not defaults, so their contents are not obvious to me.
You may or may not need a keystore. The keystore points to a file containing private key material. You need a keystore if:
1) you are implementing the server side of the protocol, or
2) you are implementing the client side and you need to authenticate yourself to the server.
There is one exception to everything stated. If you are using certain anonymous DH ciphersuites, then neither side needs either a truststore or a keystore. The connection is unauthenticated.
Wednesday, October 21, 2009
How to use an annotation.
Defining an annotation type
To define an annotation type called Meta:
Using an annotation
To use that annotation:
Using the annotation meta data ("calm down dear, it's only an example").
To print out the meta data that the annotation defines for the example above:
To define an annotation type called Meta:
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
@Retention(RetentionPolicy.RUNTIME)
public @interface Meta {
String data() default "fast";
}
Using an annotation
To use that annotation:
...
@Meta(data = "slow")
public void foo(){
...
}
...
Using the annotation meta data ("calm down dear, it's only an example").
To print out the meta data that the annotation defines for the example above:
public static void main(String[] args) {
for (Method method : MyClass.class.getMethods()) {
Annotation[] annotations = method.getAnnotations();
int num = annotations.length;
if(num==1){
System.out.println(((Meta)annotations[0]).data());
}
}
}
JAX-RS: The Java API for RESTful Web Services
JAX-RS: The Java API for RESTful Web Services
http://www.developer.com/java/article.php/3843846/JAX-RS-The-Java-API-for-RESTful-Web-Services.htm
http://www.developer.com/java/article.php/3843846/JAX-RS-The-Java-API-for-RESTful-Web-Services.htm
Non-Blocking I/O Made Possible in Java
Non-Blocking I/O Made Possible in Java
http://www.developer.com/java/article.php/3837316/Non-Blocking-IO-Made-Possible-in-Java.htm
http://www.developer.com/java/article.php/3837316/Non-Blocking-IO-Made-Possible-in-Java.htm
Monday, October 19, 2009
Learn to Use the New Annotation Feature of Java 5.0
A article for annotation of Java 5 from http://www.devx.com/Java/Article/27235/1954?pf=true
What Are Annotations?
In short, annotations are metadata or data about data. Annotations are said to annotate a Java element. An annotation indicates that the declared element should be processed in some special way by a compiler, development tool, deployment tool, or during runtime.
Annotations can be analyzed statically before and during compile time. Annotations will likely be used before compile time mainly to generate supporting classes or configuration files.For example, a code generator (XDoclet, for example) can use annotation data in an EJB implementation class to generate EJB interfaces and deployment descriptors for you, reducing both your effort and the error rate. The average developer will probably not be writing code-generation tools, so these annotation types are likely to be used out-of-the-box rather than authored anew.
Annotations will also be used for compile-time checking such as to produce warnings and errors for different failure scenarios. An example of an annotation that is used at compile time is the new @Deprecated annotation, which acts the same as the old @deprecated JavaDoc tag.
Annotations can be useful at runtime as well. Using annotations you could mark code to behave in a particular way whenever it is called.For example, you could mark some methods with a @prelog annotation.
Another way to use annotations at runtime is to use Aspect-Oriented Programming (AOP). AOP uses pointcuts—sets of points configured to executed aspects. You could define a pointcut that will execute an aspect for an annotated method. My guess is that developers would be more likely to write their own runtime annotation types than they would annotation types used for code generation and compile-time checking. Still, writing and understanding the code that accesses the annotations (the annotation consumer) at runtime is fairly advanced.
Annotating Code
Annotations fall into three categories: normal annotations, single member annotations, and marker annotations (see Table 1). Normal and single member annotations can take member values as arguments when you annotate your code.
1. Normal Annotations—Annotations that take multiple arguments. The syntax for these annotations provides the ability to pass in data for all the members defined in an annotation type.
Example: @MyNormalAnnotation(mem1="val1", mem2="val2") public void someMethod() { ... }
2. Single Member Annotations—An annotation that only takes a single argument has a more compact syntax. You don't need to provide the member name.
Example: @MySingleMemberAnnotation("a single value") public class SomeClass { ... }
3.Marker Annotations—These annotations take no parameters. They are used to mark a Java element to be processed in a particular way.
Example: @Deprecated public void doWork() { ... }
Any Java declaration can be marked with an annotation. That is, an annotation can be used on a: package, class, interface, field, method, parameter, constructor, enum (newly available in Java 1.5), or local variable. An annotation can even annotate another annotation. Such annotations are called meta-annotations.
Packages annotations are also allowed, but because packages are not explicitly declared in Java, package annotations must be declared in a source file called package-info.java in the directory containing the source files for the package.
Built-in Annotations
Java 1.5 comes packaged with seven pre-built annotations.
java.lang.Override,
java.lang.Deprecated,
java.lang.SuppressWarning,
(The follows are meta-annotation.)
java.lang.annotation.Documented,
java.lang.annotation.Inherited,
java.lang.annotation.Retention,
java.lang.annotation.Target
Declaring Annotation Types
Now that you've learned a little about the annotations that come packaged with Java 1.5, you can move on to declaring your own annotation types.
Here is a sample annotation type:
The annotation consumers are the development tools, the compiler, or a runtime library that accesses the annotation data you created when you annotated your Java code.
An example of how you can access your code during runtime using the reflection API.
What Are Annotations?
In short, annotations are metadata or data about data. Annotations are said to annotate a Java element. An annotation indicates that the declared element should be processed in some special way by a compiler, development tool, deployment tool, or during runtime.
Annotations can be analyzed statically before and during compile time. Annotations will likely be used before compile time mainly to generate supporting classes or configuration files.For example, a code generator (XDoclet, for example) can use annotation data in an EJB implementation class to generate EJB interfaces and deployment descriptors for you, reducing both your effort and the error rate. The average developer will probably not be writing code-generation tools, so these annotation types are likely to be used out-of-the-box rather than authored anew.
Annotations will also be used for compile-time checking such as to produce warnings and errors for different failure scenarios. An example of an annotation that is used at compile time is the new @Deprecated annotation, which acts the same as the old @deprecated JavaDoc tag.
Annotations can be useful at runtime as well. Using annotations you could mark code to behave in a particular way whenever it is called.For example, you could mark some methods with a @prelog annotation.
Another way to use annotations at runtime is to use Aspect-Oriented Programming (AOP). AOP uses pointcuts—sets of points configured to executed aspects. You could define a pointcut that will execute an aspect for an annotated method. My guess is that developers would be more likely to write their own runtime annotation types than they would annotation types used for code generation and compile-time checking. Still, writing and understanding the code that accesses the annotations (the annotation consumer) at runtime is fairly advanced.
Annotating Code
Annotations fall into three categories: normal annotations, single member annotations, and marker annotations (see Table 1). Normal and single member annotations can take member values as arguments when you annotate your code.
1. Normal Annotations—Annotations that take multiple arguments. The syntax for these annotations provides the ability to pass in data for all the members defined in an annotation type.
Example: @MyNormalAnnotation(mem1="val1", mem2="val2") public void someMethod() { ... }
2. Single Member Annotations—An annotation that only takes a single argument has a more compact syntax. You don't need to provide the member name.
Example: @MySingleMemberAnnotation("a single value") public class SomeClass { ... }
3.Marker Annotations—These annotations take no parameters. They are used to mark a Java element to be processed in a particular way.
Example: @Deprecated public void doWork() { ... }
Any Java declaration can be marked with an annotation. That is, an annotation can be used on a: package, class, interface, field, method, parameter, constructor, enum (newly available in Java 1.5), or local variable. An annotation can even annotate another annotation. Such annotations are called meta-annotations.
Packages annotations are also allowed, but because packages are not explicitly declared in Java, package annotations must be declared in a source file called package-info.java in the directory containing the source files for the package.
Built-in Annotations
Java 1.5 comes packaged with seven pre-built annotations.
(The follows are meta-annotation.)
Declaring Annotation Types
Now that you've learned a little about the annotations that come packaged with Java 1.5, you can move on to declaring your own annotation types.
Here is a sample annotation type:
public @interface MyAnnotationType {
int someValue();
String someOtherValue();
String yesSomeOtherValue() default "[blank]";
}
The annotation consumers are the development tools, the compiler, or a runtime library that accesses the annotation data you created when you annotated your Java code.
An example of how you can access your code during runtime using the reflection API.
// The Annotation Type
import java.lang.annotation.Retention;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
@Retention(RUNTIME)
public @interface GreetsTheWorld {
public String value();
}
// The Annotated Class
@GreetsTheWorld("Hello, class!")
public class HelloWorld {
@GreetsTheWorld("Hello, field!")
public String greetingState;
@GreetsTheWorld("Hello, constructor!")
public HelloWorld() {
}
@GreetsTheWorld("Hello, method!")
public void sayHi() {
}
}
// The Annotation Consumer
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class HelloWorldAnnotationTest
{
public static void main( String[] args ) throws Exception
{
//access the class annotation
Classclazz = HelloWorld.class;
System.out.println( clazz.getAnnotation( GreetsTheWorld.class ) );
//access the constructor annotation
Constructorconstructor =
clazz.getConstructor((Class[]) null);
System.out.println(
constructor.getAnnotation(GreetsTheWorld.class));
//access the method annotation
Method method = clazz.getMethod( "sayHi" );
System.out.println(method.getAnnotation(GreetsTheWorld.class));
//access the field annotation
Field field = clazz.getField("greetingState");
System.out.println(field.getAnnotation(GreetsTheWorld.class));
}
}
Sunday, October 18, 2009
Why did Hibernate update my database?
From http://blog.xebia.com/2009/04/06/why-did-hibernate-update-my-database/
Hibernate is a sophisticated ORM framework, that will manage the state of your persistent data for you. Handing over the important but difficult task of managing persistent state of your application to a framework has numerous advantages, but one of the disadvantages is that you sort of lose control over what happens where and when. One example of this is the dirty checking feature that Hibernate provides. By doing dirty checking, Hibernate determines what data needs to be updated in your database. In many cases, this feature is quite useful and will work without any issues, but sometimes you might find that Hibernate decides to update something that you did not expect. Finding out why his happened can be a rather difficult task.
I was asked to look into some issue with a StaleObjectState exception the other day. StaleObjectState exceptions are used by hibernate to signal an optimistic locking conflict: While some user (or process) tries to save a data item, the same data item has already been changed in the underlying database since it was last read. Now the problem was that the process that was throwing the exception was the only process that was supposed to change that data. From a functional point of view there could not have been any other user or process that changed the data in the meantime. So what was going on?
Digging around in the log for some time, we found that the data was updated by some other process that was supposed to only read that data. Somehow Hibernate decided that the data read by that process had become dirty and should be saved. So now he had to find out why Hibernate thought that data was dirty.
Hibernate can perform dirty checking in several places in an application:
1. When a transaction is being committed or a session is being flushed, obviously, because at that time changes made in the transaction or session should be persisted to the database
2. When a query is being executed. To prevent missing changes that still reside in memory, Hibernate will flush data that might be queried to the database just before executing the query. It tries to be picky about this and not flush everything all the time, but only the data that might be queried.
It is quite difficult to check all these places to find out where the data is being find dirty, especially when the process executes several queries.
To find out why Hibernate deems the data to be dirty, we have to dig into the Hibernate internals and start debugging the framework code. The Hibernate architecture is quite complex. There are a number of classes that are involved in dirty checking and updating entities:
The DefaultFlushEntityEventListener determines what fields are dirty. The internals of this class work on the list of properties of an entity and two lists of values: the values as loaded from the database and the values as currently known to the session. It delegates finding out the ''dirty-ness' of a field to the registered Interceptor and to the types of the properties.
The EntityUpdateAction is responsible for doing the update itself. An object of this type will be added to a ActionQueue to be executed when a session is flushed.
These classes show some of the patterns used in the internals of Hibernate: eventing and action queuing. These patterns make the architecture of the framework very clear, but they also make following what is going on sometimes very hard...
As previously explained, flushing happens quite often and setting a breakpoint in the DefaultFlushEntityEventListener is not usually a good idea, because it will get hit very often. An EntityUpdateAction, however, will only get created when an update will be issued to the underlying database. So to find out what the problem was, I set a breakpoint in the constructor and backtracked from there. It turned out Hibernate could not determine the dirty state of the object and therefor decided to update the entity just to be save.
As mentioned eralier, Hibernate uses the "loaded state" to determine whether an object is dirty. This is the state of the object (the values of its properties) when loaded form the database. Hibernate stores this information in its persistence context. When dirty checking, Hibernate compares these values to the current values. When the "loaded state" is not available, Hibernate effectively cannot do dirty checking and deems the object dirty. The only scenario, however, in which the loaded state is unavailable is when the object has been re-attached to the session and thus not loaded from the database. The process I was looking into, however did not work with detached data.
There is one other scenario in which Hibernate will lose the "loaded state" of the data: When the session is being cleared. This operation will discard all state in the persistence context completely. It is quite a dangerous operation to use in your application code and it should only be invoked if you are very sure of what you're doing. In our situation, the session was being flushed and cleared at some point, leading to the unwanted updates and eventually the StaleObjectStateExceptions. An unwanted situation indeed. After removing the clear, the updates where gone and the bug was fixed.
Using Hibernate can save a developer a lot of time, when things are running smoothly. When a problem is encountered, a lot of specialized Hibernate knowledge and a considerable amount of time is often needed to diagnose and solve it.
Hibernate is a sophisticated ORM framework, that will manage the state of your persistent data for you. Handing over the important but difficult task of managing persistent state of your application to a framework has numerous advantages, but one of the disadvantages is that you sort of lose control over what happens where and when. One example of this is the dirty checking feature that Hibernate provides. By doing dirty checking, Hibernate determines what data needs to be updated in your database. In many cases, this feature is quite useful and will work without any issues, but sometimes you might find that Hibernate decides to update something that you did not expect. Finding out why his happened can be a rather difficult task.
I was asked to look into some issue with a StaleObjectState exception the other day. StaleObjectState exceptions are used by hibernate to signal an optimistic locking conflict: While some user (or process) tries to save a data item, the same data item has already been changed in the underlying database since it was last read. Now the problem was that the process that was throwing the exception was the only process that was supposed to change that data. From a functional point of view there could not have been any other user or process that changed the data in the meantime. So what was going on?
Digging around in the log for some time, we found that the data was updated by some other process that was supposed to only read that data. Somehow Hibernate decided that the data read by that process had become dirty and should be saved. So now he had to find out why Hibernate thought that data was dirty.
Hibernate can perform dirty checking in several places in an application:
1. When a transaction is being committed or a session is being flushed, obviously, because at that time changes made in the transaction or session should be persisted to the database
2. When a query is being executed. To prevent missing changes that still reside in memory, Hibernate will flush data that might be queried to the database just before executing the query. It tries to be picky about this and not flush everything all the time, but only the data that might be queried.
It is quite difficult to check all these places to find out where the data is being find dirty, especially when the process executes several queries.
To find out why Hibernate deems the data to be dirty, we have to dig into the Hibernate internals and start debugging the framework code. The Hibernate architecture is quite complex. There are a number of classes that are involved in dirty checking and updating entities:
The DefaultFlushEntityEventListener determines what fields are dirty. The internals of this class work on the list of properties of an entity and two lists of values: the values as loaded from the database and the values as currently known to the session. It delegates finding out the ''dirty-ness' of a field to the registered Interceptor and to the types of the properties.
The EntityUpdateAction is responsible for doing the update itself. An object of this type will be added to a ActionQueue to be executed when a session is flushed.
These classes show some of the patterns used in the internals of Hibernate: eventing and action queuing. These patterns make the architecture of the framework very clear, but they also make following what is going on sometimes very hard...
As previously explained, flushing happens quite often and setting a breakpoint in the DefaultFlushEntityEventListener is not usually a good idea, because it will get hit very often. An EntityUpdateAction, however, will only get created when an update will be issued to the underlying database. So to find out what the problem was, I set a breakpoint in the constructor and backtracked from there. It turned out Hibernate could not determine the dirty state of the object and therefor decided to update the entity just to be save.
As mentioned eralier, Hibernate uses the "loaded state" to determine whether an object is dirty. This is the state of the object (the values of its properties) when loaded form the database. Hibernate stores this information in its persistence context. When dirty checking, Hibernate compares these values to the current values. When the "loaded state" is not available, Hibernate effectively cannot do dirty checking and deems the object dirty. The only scenario, however, in which the loaded state is unavailable is when the object has been re-attached to the session and thus not loaded from the database. The process I was looking into, however did not work with detached data.
There is one other scenario in which Hibernate will lose the "loaded state" of the data: When the session is being cleared. This operation will discard all state in the persistence context completely. It is quite a dangerous operation to use in your application code and it should only be invoked if you are very sure of what you're doing. In our situation, the session was being flushed and cleared at some point, leading to the unwanted updates and eventually the StaleObjectStateExceptions. An unwanted situation indeed. After removing the clear, the updates where gone and the bug was fixed.
Using Hibernate can save a developer a lot of time, when things are running smoothly. When a problem is encountered, a lot of specialized Hibernate knowledge and a considerable amount of time is often needed to diagnose and solve it.
Friday, October 16, 2009
JPA and Hibernate Tutorial
A tutorial website of hibernate.
http://www.hibernate-training-guide.com/index.html
Hibernate 3 Annotations Tutorial
http://loianegroner.com/2010/06/hibernate-3-annotations-tutorial/
Two slides from Sun.
http://www.slideshare.net/caroljmcdonald/td09jpabestpractices2
http://developers.sun.com/learning/javaoneonline/2007/pdf/TS-4902.pdf?
http://java.sun.com/javaee/5/docs/tutorial/doc/bnbqw.html
Basic Java Persistence API Best Practices
http://www.oracle.com/technology/pub/articles/marx-jpa.html
An IBM Book
http://books.google.ca/books?id=ko5KTfIHjasC&printsec=frontcover&source=gbs_v2_summary_r&cad=0#v=onepage&q=&f=false
http://www.hibernate-training-guide.com/index.html
Hibernate 3 Annotations Tutorial
http://loianegroner.com/2010/06/hibernate-3-annotations-tutorial/
Two slides from Sun.
http://www.slideshare.net/caroljmcdonald/td09jpabestpractices2
http://developers.sun.com/learning/javaoneonline/2007/pdf/TS-4902.pdf?
http://java.sun.com/javaee/5/docs/tutorial/doc/bnbqw.html
Basic Java Persistence API Best Practices
http://www.oracle.com/technology/pub/articles/marx-jpa.html
An IBM Book
http://books.google.ca/books?id=ko5KTfIHjasC&printsec=frontcover&source=gbs_v2_summary_r&cad=0#v=onepage&q=&f=false
Generic Repository - Generic DB access?
Generic Repository (grepo) is an open source (ASLv2) framework for Java which allows you to access (database) repositories in a generic and consistent manner.
The main features of the framework are:
* generic support for Hibernate based DAOs
* generic support for Jpa based DAOs
* generic support for executing database stored-procedures and functions
* highly customizable
The "Generic Query" component allows to access databases using SQL queries. Currently the following ORM (Object Relational Mapping) tools/APIs are supported:
* Native Hibernate API
* Java Persistence API
The "Generic Procedure" component allows to access databases using PLSQL (that is calling stored procedures and/or functions) without requiring custom implementations - gprocedure is build on top of the Spring (JDBC) framework.
History
Daniel Guggi
The Generic Repository Framework (grepo) has its origins back in 2007. I started development after reading Per Mellqvist's article "Don't repeat the DAO". My employer BearingPoint INFONOVA GmbH develops and maintains various business applications for its customers (mainly telecom providers). The software is developed/extended by various development (scrum) teams. Even though we have a professional development environment (using professional/good tools and frameworks etc...) and development guidelines (detailed coding conventions etc...) it turned out that the data access layers in our software products got quite fragmented, inconsistent and bloated - mainly because of big development teams and large software products, the typicall daily project-stress and the always reoccoring (similar) boilerplate code for database access logic. So we started developing a framework which in turn was tuned and improved in order to achieve the following main goals for our software products:
* Ensure coding conventions and guidelines.
* Avoid boilerplate code for database access logic.
* Improve development time and code quality.
Finally we came up with a framework based on Spring and Hibernate. The framework is integrated in our software products for quite a while right now and is used for basically (at least about 90%) all new database related access objects. We are quite happy with the result and thus we decided to make it open source - and so the Generic Repository project was born.
The main features of the framework are:
* generic support for Hibernate based DAOs
* generic support for Jpa based DAOs
* generic support for executing database stored-procedures and functions
* highly customizable
The "Generic Query" component allows to access databases using SQL queries. Currently the following ORM (Object Relational Mapping) tools/APIs are supported:
* Native Hibernate API
* Java Persistence API
The "Generic Procedure" component allows to access databases using PLSQL (that is calling stored procedures and/or functions) without requiring custom implementations - gprocedure is build on top of the Spring (JDBC) framework.
History
Daniel Guggi
The Generic Repository Framework (grepo) has its origins back in 2007. I started development after reading Per Mellqvist's article "Don't repeat the DAO". My employer BearingPoint INFONOVA GmbH develops and maintains various business applications for its customers (mainly telecom providers). The software is developed/extended by various development (scrum) teams. Even though we have a professional development environment (using professional/good tools and frameworks etc...) and development guidelines (detailed coding conventions etc...) it turned out that the data access layers in our software products got quite fragmented, inconsistent and bloated - mainly because of big development teams and large software products, the typicall daily project-stress and the always reoccoring (similar) boilerplate code for database access logic. So we started developing a framework which in turn was tuned and improved in order to achieve the following main goals for our software products:
* Ensure coding conventions and guidelines.
* Avoid boilerplate code for database access logic.
* Improve development time and code quality.
Finally we came up with a framework based on Spring and Hibernate. The framework is integrated in our software products for quite a while right now and is used for basically (at least about 90%) all new database related access objects. We are quite happy with the result and thus we decided to make it open source - and so the Generic Repository project was born.
Echo is an open-source framework for developing rich web applications.
I ever used the Echo 1.x and it was the first framework developing web application using server side development I had seen. I did a deep research on it 2004. I think the frameworks like it should be the future of web application development. But it isn't so far. Maybe I am wrong, but I still like these RIA frameworks.
See http://www.nextapp.com/products/ for detail.
See http://www.nextapp.com/products/ for detail.
Vaadin is a web application framework for Rich Internet Applications (RIA).
Another server side implementation for web application development. It is really powerful - Vaadin.
See http://vaadin.com/home for detail.
See http://vaadin.com/home for detail.
how to access properties file in Spring
http://technologiquepanorama.wordpress.com/2009/03/17/how_to_access_properties_file_in-spring/
Saturday, October 10, 2009
Configuring a JBoss + Spring + JPA (Hibernate) + JTA web application
(From http://www.swview.org/node/214)
Here's how one might go about deploying a Spring application in JBoss (4.something) that uses JPA with Hibernate as the provider for persistence and JTA for transaction demarcation.
1. Define the Spring configuration file in the web.xml file
<context-param>
<description>Spring configuration file</description>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/applicationContext.xml</param-value>
</context-param>
2. Define the Spring loader in the web.xml file
<listener>
<description>Spring Loader</description>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
3. Define the persistence unit reference in the web.xml file (which in fact has no effect until the Servlet container supports Servlet spec 2.5):
<persistence-unit-ref>
<description>
Persistence unit for the bank application.
</description>
<persistence-unit-ref-name>
persistence/BankAppPU
</persistence-unit-ref-name>
<persistence-unit-name>BankAppPU</persistence-unit-name>
</persistence-unit-ref>
* Note that this is what enables "" which has been commented out in the below given Spring configuration file.
* For the above to work well, your web.xml should start like this (note the version 2.5):
<web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
4. Here's the persistence.xml file. Make the changes to the as you have defined in your system (for example in a file like JBOSS_HOME/server/default/deploy/bank-ds.xml - See JBOSS_HOME/docs/examples/jca/ for templates).
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="BankAppPU" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:BankAppDS</jta-data-source>
<properties>
<property name="hibernate.transaction.manager_lookup_class" value="org.hibernate.transaction.JBossTransactionManagerLookup"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="jboss.entity.manager.factory.jndi.name" value="java:/BankAppPU"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
</properties>
</persistence-unit>
</persistence>
5. Here's a sample Spring configuration file (applicationContext.xml):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jee="http://www.springframework.org/schema/jee"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-2.5.xsd">
<!-- In a fully J5EE compatible environment, the following xml tag should work in accessing the EMF -->
<!--
<jee:jndi-lookup id="entityManagerFactory" jndi-name="java:/BankAppPU"/>
-->
<!-- Hack for JBoss 4.something until full compliance is reached -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalEntityManagerFactoryBean">
<property name="persistenceUnitName" value="BankAppPU"/>
</bean>
<!-- Let's access the JTA transaction manager of the application server -->
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="transactionManagerName" value="java:/TransactionManager"/>
<property name="userTransactionName" value="UserTransaction"/>
</bean>
<!-- Let's define a DAO that uses the EMF -->
<bean id="accountHolderDAO" class="bankapp.dao.AccountHolderDAO">
<property name="emf" ref="entityManagerFactory"/>
</bean>
<!-- This is a service object that we want to make transactional.
You will have an interface implemented (AccountManager) in the class.
-->
<bean id="accountManager" class="bankapp.AccountManagerImpl">
<property name="accountHolderDAO" ref="accountHolderDAO"/>
</bean>
<!-- The transactional advice (i.e. what 'happens'; see the <aop:advisor/> bean below) -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- the transactional semantics... -->
<tx:attributes>
<!-- all methods starting with 'get' are read-only transactions -->
<tx:method name="get*" read-only="true"/>
<!-- other methods use the default transaction settings (see below) -->
<tx:method name="*" read-only="false" />
</tx:attributes>
</tx:advice>
<!-- ensure that the above transactional advice runs for execution
of any operation defined by the AccountManager interface -->
<aop:config>
<aop:pointcut id="accountManagerOperation",
expression="execution(* bankapp.AccountManager.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="accountManagerOperation"/>
</aop:config>
</beans>
6. Here's the sample AccountManagerImpl:
7. Here's the sample AccountHolderDAO:
You will have some other code accessing the Spring bean "accountManager" and invoke the createAccountHolder() with the required parameters. Things should work well.
Here's how one might go about deploying a Spring application in JBoss (4.something) that uses JPA with Hibernate as the provider for persistence and JTA for transaction demarcation.
1. Define the Spring configuration file in the web.xml file
<context-param>
<description>Spring configuration file</description>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/applicationContext.xml</param-value>
</context-param>
2. Define the Spring loader in the web.xml file
<listener>
<description>Spring Loader</description>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
3. Define the persistence unit reference in the web.xml file (which in fact has no effect until the Servlet container supports Servlet spec 2.5):
<persistence-unit-ref>
<description>
Persistence unit for the bank application.
</description>
<persistence-unit-ref-name>
persistence/BankAppPU
</persistence-unit-ref-name>
<persistence-unit-name>BankAppPU</persistence-unit-name>
</persistence-unit-ref>
* Note that this is what enables "
* For the above to work well, your web.xml should start like this (note the version 2.5):
<web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
4. Here's the persistence.xml file. Make the changes to the
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="BankAppPU" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:BankAppDS</jta-data-source>
<properties>
<property name="hibernate.transaction.manager_lookup_class" value="org.hibernate.transaction.JBossTransactionManagerLookup"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="jboss.entity.manager.factory.jndi.name" value="java:/BankAppPU"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
</properties>
</persistence-unit>
</persistence>
5. Here's a sample Spring configuration file (applicationContext.xml):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jee="http://www.springframework.org/schema/jee"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-2.5.xsd">
<!-- In a fully J5EE compatible environment, the following xml tag should work in accessing the EMF -->
<!--
<jee:jndi-lookup id="entityManagerFactory" jndi-name="java:/BankAppPU"/>
-->
<!-- Hack for JBoss 4.something until full compliance is reached -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalEntityManagerFactoryBean">
<property name="persistenceUnitName" value="BankAppPU"/>
</bean>
<!-- Let's access the JTA transaction manager of the application server -->
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="transactionManagerName" value="java:/TransactionManager"/>
<property name="userTransactionName" value="UserTransaction"/>
</bean>
<!-- Let's define a DAO that uses the EMF -->
<bean id="accountHolderDAO" class="bankapp.dao.AccountHolderDAO">
<property name="emf" ref="entityManagerFactory"/>
</bean>
<!-- This is a service object that we want to make transactional.
You will have an interface implemented (AccountManager) in the class.
-->
<bean id="accountManager" class="bankapp.AccountManagerImpl">
<property name="accountHolderDAO" ref="accountHolderDAO"/>
</bean>
<!-- The transactional advice (i.e. what 'happens'; see the <aop:advisor/> bean below) -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- the transactional semantics... -->
<tx:attributes>
<!-- all methods starting with 'get' are read-only transactions -->
<tx:method name="get*" read-only="true"/>
<!-- other methods use the default transaction settings (see below) -->
<tx:method name="*" read-only="false" />
</tx:attributes>
</tx:advice>
<!-- ensure that the above transactional advice runs for execution
of any operation defined by the AccountManager interface -->
<aop:config>
<aop:pointcut id="accountManagerOperation",
expression="execution(* bankapp.AccountManager.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="accountManagerOperation"/>
</aop:config>
</beans>
6. Here's the sample AccountManagerImpl:
public class AccountManagerImpl implements AccountManager {
/** Creates a new instance of AccountManagerImpl */
public AccountManagerImpl() {
}
private AccountHolderDAO accountHolderDAO;
public AccountHolder createAccountHolder(AccountHolder accountHolder) throws BankException {
return accountHolderDAO.create(accountHolder);
}
public AccountHolderDAO getAccountHolderDAO() {
return accountHolderDAO;
}
public void setAccountHolderDAO(AccountHolderDAO accountHolderDAO) {
this.accountHolderDAO = accountHolderDAO;
}
}
7. Here's the sample AccountHolderDAO:
public class AccountHolderDAO {
/** Creates a new instance of AccountHolderDAO */
public AccountHolderDAO() {
}
private EntityManagerFactory emf;
public EntityManagerFactory getEmf() {
return emf;
}
public void setEmf(EntityManagerFactory emf) {
this.emf = emf;
}
public AccountHolder create(AccountHolder newAccountHolder) throws BankException {
try {
// JTA Transaction assumed to have been started by AccountManager (Spring tx advice)
EntityManager em = emf.createEntityManager();
//em.getTransaction().begin(); - Not required
em.persist(newAccountHolder);
//em.getTransaction().commit(); - Not required
return newAccountHolder;
// JTA Transaction will be completed by Spring tx advice
} catch (Exception e) {
throw new BankException("Account creation failed" + e.getMessage(), e);
}
}
}
You will have some other code accessing the Spring bean "accountManager" and invoke the createAccountHolder() with the required parameters. Things should work well.
Java Persistence API
The Java Persistence API is a POJO persistence API for object/relational mapping. It contains a full object/relational mapping specification supporting the use of Java language metadata annotations and/or XML descriptors to define the mapping between Java objects and a relational database. Java Persistence API is usable both within Java SE environments as well as within Java EE.
It supports a rich, SQL-like query language (which is a significant extension upon EJB QL) for both static and dynamic queries. It also supports the use of pluggable persistence providers.
The Java Persistence API originated as part of the work of the JSR 220 Expert Group to simplify EJB CMP entity beans. It soon became clear to the expert group, however, that a simplification of EJB CMP was not enough, and that what was needed was a POJO persistence framework in line with other O/R mapping technologies available in the industry. The Java Persistence API draws upon the best ideas from persistence technologies such as Hibernate, TopLink, and JDO.
It supports a rich, SQL-like query language (which is a significant extension upon EJB QL) for both static and dynamic queries. It also supports the use of pluggable persistence providers.
The Java Persistence API originated as part of the work of the JSR 220 Expert Group to simplify EJB CMP entity beans. It soon became clear to the expert group, however, that a simplification of EJB CMP was not enough, and that what was needed was a POJO persistence framework in line with other O/R mapping technologies available in the industry. The Java Persistence API draws upon the best ideas from persistence technologies such as Hibernate, TopLink, and JDO.
Thursday, October 08, 2009
What new in JSF 2?
What new in JSF 2?
The follow link gives out a lot of info. Andy Schwartz has created a fantastic introduction to the new features of JavaServer Faces 2.
http://andyschwartz.wordpress.com/2009/07/31/whats-new-in-jsf-2/
The follow is a slide of introduction of JSF.
http://horstmann.com/presentations/javaone-2009-sl/what-is-new-in-jsf2.html#(1)
JSF 1.x Part of Java EE Standard (JSR 127, 252)
Component oriented web framework
Two implementations: Sun, Apache
Veeeery extensible
Tool support
Third party component libraries
JSF 2.0Part of Java EE 6 (JSR 314)
Reduced XML configuration
Better error handling
Ajax
Support for GET requests
Easier component authoring
Resource handling
Lots of plumbing for tool builders
Easy NavigationBefore:

Managed Bean Annotations

FaceletsWas third party extension (Jacob Hookom)
Now part of the standard
The preferred view handler in JSF
No more JSP mess
MUCH better error messages
Page composition
Bookmarkable URLsIn JSF 1.x, everything is a POST
Browser bar URL one step behind
Can't be bookmarked
JSF 2.x supports GET requests
New tags h:button, h:link
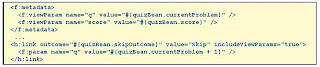
View Parameters
.Bound to beans when request comes in
.Can be attached to next request
Composite ComponentsMade up of simpler components
Example: Login component with username/password fields
True JSF components
Can attach validators, listeners
Specified with XHTML+composite tags

Ajax

Minor Features
Resource loading
Standard resources directory
h:graphicImage, h:outputStylesheet, h:outputScript have library, name attributes
<h:outputStylesheet library="css" name="styles.css" />
Dynamic versioning
Botched attempt at i18n
New scopes
View scope
Flash
14 new events
Most useful for app developers: preRenderView, postValidate
<f:event type="postValidate" listener="#{user.validate}"/>
How to PlayRI is feature-complete but not bug-free
Download JSF 2.0 RI from http://javaserverfaces.dev.java.net/
Works with Tomcat
Or download Glassfish v3 Prelude
Or Netbeans 6.7 RC
Caveat: These may not have the latest JSF 2.0 implementations today
Looking ForwardComponent libraries for 2.0
IceFaces
RichFaces
Trinidad
Cruft removal
Integration with Web Beans (JSR 299)
The follow link gives out a lot of info. Andy Schwartz has created a fantastic introduction to the new features of JavaServer Faces 2.
http://andyschwartz.wordpress.com/2009/07/31/whats-new-in-jsf-2/
The follow is a slide of introduction of JSF.
http://horstmann.com/presentations/javaone-2009-sl/what-is-new-in-jsf2.html#(1)
JSF 1.x Part of Java EE Standard (JSR 127, 252)
Component oriented web framework
Two implementations: Sun, Apache
Veeeery extensible
Tool support
Third party component libraries
JSF 2.0Part of Java EE 6 (JSR 314)
Reduced XML configuration
Better error handling
Ajax
Support for GET requests
Easier component authoring
Resource handling
Lots of plumbing for tool builders
Easy NavigationBefore:

Managed Bean Annotations

FaceletsWas third party extension (Jacob Hookom)
Now part of the standard
The preferred view handler in JSF
No more JSP mess
MUCH better error messages
Page composition
Bookmarkable URLsIn JSF 1.x, everything is a POST
Browser bar URL one step behind
Can't be bookmarked
JSF 2.x supports GET requests
New tags h:button, h:link
View Parameters
.Bound to beans when request comes in
.Can be attached to next request

Composite ComponentsMade up of simpler components
Example: Login component with username/password fields
True JSF components
Can attach validators, listeners
Specified with XHTML+composite tags

Ajax

Minor Features
Resource loading
Standard resources directory
h:graphicImage, h:outputStylesheet, h:outputScript have library, name attributes
<h:outputStylesheet library="css" name="styles.css" />
Dynamic versioning
Botched attempt at i18n
New scopes
View scope
Flash
14 new events
Most useful for app developers: preRenderView, postValidate
<f:event type="postValidate" listener="#{user.validate}"/>
How to PlayRI is feature-complete but not bug-free
Download JSF 2.0 RI from http://javaserverfaces.dev.java.net/
Works with Tomcat
Or download Glassfish v3 Prelude
Or Netbeans 6.7 RC
Caveat: These may not have the latest JSF 2.0 implementations today
Looking ForwardComponent libraries for 2.0
IceFaces
RichFaces
Trinidad
Cruft removal
Integration with Web Beans (JSR 299)
RichFaces - another wheel from JBoss.
RichFaces 3.3.2 GA finally available for donwloads! Numerous bug fixes, optimizations and community RFCs are ready for the review and usage!
RichFaces is a component library for JSF and an advanced framework for easily integrating AJAX capabilities into business applications.
100+ AJAX enabled components in two libraries
a4j: page centric AJAX controls
rich: self contained, ready to use components
Whole set of JSF benefits while working with AJAX
Skinnability mechanism
Component Development Kit (CDK)
Dynamic resources handling
Testing facilities for components, actions, listeners, and pages
Broad cross-browser support
Large and active community
JSF 2 and RichFaces 4
We are working hard on RichFaces 4.0 which will have full JSF 2 integration. That is not all though, here is a summary of updates and features:
Redesigned modular repository and build system.
Simplified Component Development Kit with annotations, faces-config extensions, advanced templates support and more..
Ajax framework improvements extending the JSF 2 specification.
Component review for consistency, usability, and redesign following semantic HTML principles where possible.
Both server-side and client-side performance optimization.
Strict code clean-up and review.
RichFaces is a component library for JSF and an advanced framework for easily integrating AJAX capabilities into business applications.
100+ AJAX enabled components in two libraries
a4j: page centric AJAX controls
rich: self contained, ready to use components
Whole set of JSF benefits while working with AJAX
Skinnability mechanism
Component Development Kit (CDK)
Dynamic resources handling
Testing facilities for components, actions, listeners, and pages
Broad cross-browser support
Large and active community
JSF 2 and RichFaces 4
We are working hard on RichFaces 4.0 which will have full JSF 2 integration. That is not all though, here is a summary of updates and features:
Redesigned modular repository and build system.
Simplified Component Development Kit with annotations, faces-config extensions, advanced templates support and more..
Ajax framework improvements extending the JSF 2 specification.
Component review for consistency, usability, and redesign following semantic HTML principles where possible.
Both server-side and client-side performance optimization.
Strict code clean-up and review.
ICEfaces - the best JSF framework
ICEfaces has been supported by NetBeans IDE. It looks pretty good and ease the developer to develop web application visually.
ICEfaces 1.8.2 Released
ICEfaces 1.8.2 is an official release that includes over 160 fixes and improvements.
Notable changes include:
• All-new support for "cookieless" mode operation for synchronous ICEfaces applications (deployed to browsers with cookies disabled).
• Enhanced keyboard navigation for the menuBar, menuPopup, panelCollapsible, panelTabSet, and tree components.
• The panelTab component now supports an optional label facet for defining arbitrarily complex labels.
• Enhanced dataExporter: define which columns & rows to export, seamless operation with dataPaginator, portlet support, and improved robustness.
• Improved panelTooltip: smarter positioning, mouse tracking, and customizable display event triggers (hover, click, etc.).
• Support for nested modal panelPopups.
• The inputFile component now supports optional "autoUpload" mode.
• The graphicImage component now supports all ICEfaces Resource APIs for specifying image resources.
• The outputResource component now has improved special character support for resource file-names.
• Rendering performance optimizations have been made to the dataTable, panelGroup, panelSeries, and menuBar components.
• Updated Component Showcase sample application illustrating new component capabilities.
ICEfaces 1.8.2 Released
ICEfaces 1.8.2 is an official release that includes over 160 fixes and improvements.
Notable changes include:
• All-new support for "cookieless" mode operation for synchronous ICEfaces applications (deployed to browsers with cookies disabled).
• Enhanced keyboard navigation for the menuBar, menuPopup, panelCollapsible, panelTabSet, and tree components.
• The panelTab component now supports an optional label facet for defining arbitrarily complex labels.
• Enhanced dataExporter: define which columns & rows to export, seamless operation with dataPaginator, portlet support, and improved robustness.
• Improved panelTooltip: smarter positioning, mouse tracking, and customizable display event triggers (hover, click, etc.).
• Support for nested modal panelPopups.
• The inputFile component now supports optional "autoUpload" mode.
• The graphicImage component now supports all ICEfaces Resource APIs for specifying image resources.
• The outputResource component now has improved special character support for resource file-names.
• Rendering performance optimizations have been made to the dataTable, panelGroup, panelSeries, and menuBar components.
• Updated Component Showcase sample application illustrating new component capabilities.
Monday, September 21, 2009
PrimeFaces UI 0.9.3 is released/IPhone App Development with JSF
(From http://www.theserverside.com/news/thread.tss?thread_id=58131)
UI Components 0.9.3 features the TouchFaces mobile UI kit, 5 new components, improved portlet support, enhanced datatable and various improvements.
* TouchFaces - UI Development kit for mobile devices mainly iphone
* New component : FileUpload (Reimplemented)
* New component : Tooltip (Reimplemented)
* New component : PickList
* New component : HotKey
* New component : Virtual Keyboard
* Easy row selection, ajax pagination, data filtering and lazy loading enhancements to DataTable
* Significantly improved portal support for JSR168 and JSR268 portlets.
* Pojo and Converter support for AutoComplete
(From http://www.theserverside.com/news/thread.tss?thread_id=57877)
TouchFaces is a new subproject of PrimeFaces targeting the mobile
devices mainly iphone. Applications created with TouchFaces have the native look and feel of an IPhone applications and still benefit from the Java/JSF infrastructure. In addition TouchFaces depends on the PrimeFaces UI so ajax is built-in.
There's a 10 minute getting started screencast available online.
Website: http://primefaces.prime.com.tr/en/
UI Components 0.9.3 features the TouchFaces mobile UI kit, 5 new components, improved portlet support, enhanced datatable and various improvements.
* TouchFaces - UI Development kit for mobile devices mainly iphone
* New component : FileUpload (Reimplemented)
* New component : Tooltip (Reimplemented)
* New component : PickList
* New component : HotKey
* New component : Virtual Keyboard
* Easy row selection, ajax pagination, data filtering and lazy loading enhancements to DataTable
* Significantly improved portal support for JSR168 and JSR268 portlets.
* Pojo and Converter support for AutoComplete
(From http://www.theserverside.com/news/thread.tss?thread_id=57877)
TouchFaces is a new subproject of PrimeFaces targeting the mobile
devices mainly iphone. Applications created with TouchFaces have the native look and feel of an IPhone applications and still benefit from the Java/JSF infrastructure. In addition TouchFaces depends on the PrimeFaces UI so ajax is built-in.
There's a 10 minute getting started screencast available online.
Website: http://primefaces.prime.com.tr/en/
User specified error message
Error messages starting from -20000 until -20999 are user specified error messages.
Oracle provides these range of codes so applications can raise an application specific error, which will be displayed after the chosen code.
This is done using the raise_application_error pl/sql function.
You'll have to contact the application provider should you want to have more detail about the error message.
Unless the error message is of an Oracle application or functionality, it is useless to contact Oracle for these errors.
Imagine I have a procedure which takes an argument. This arguments needs to be between 0 and 100:
The same thing happened with you, if you receive this error with one of our applications, you need to contact us in order to solve this problem.
So the only one who can help is the application vendor or service provider.
Oracle provides these range of codes so applications can raise an application specific error, which will be displayed after the chosen code.
This is done using the raise_application_error pl/sql function.
You'll have to contact the application provider should you want to have more detail about the error message.
Unless the error message is of an Oracle application or functionality, it is useless to contact Oracle for these errors.
Imagine I have a procedure which takes an argument. This arguments needs to be between 0 and 100:
create or replace procedure add_salary(pRaise number) is begin if pRaise not between 0 and 100 then raise_application_error(-20000, 'Raise need to be between 0 and 100'); end if; -- do further processing end; / Procedure created. SQL>Now we test the procedure with a valid argument:
SQL> exec add_salary(0); PL/SQL procedure successfully completed.And now with an invalid argument:
SQL> exec add_salary(110); BEGIN add_salary(110); END; * ERROR at line 1: ORA-20000: Raise need to be between 0 and 100 ORA-06512: at "DEV01.ADD_SALARY", line 4 ORA-06512: at line 1As one can see, we raised a custom error -20000 with a user defined error message.
The same thing happened with you, if you receive this error with one of our applications, you need to contact us in order to solve this problem.
So the only one who can help is the application vendor or service provider.
Handle Oracle PL/SQL Exception.
Few use the Oracle stored procedure in Java application. Today, I have to learn it as there is a modification in stored procedure. By the searching, got a link from Oracle website. It is a official help and pretty good. But I really hate to use them in application if not very very necessary. Anyway, just put here for a reference.
http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14261/errors.htm#i1863
http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14261/errors.htm#i1863
Thursday, July 23, 2009
GMaps4JSF 1.1.2 release
GMaps4JSF 1.1.2 release: "GMaps4JSF 1.1.2 release"
JSF is really a good framework and this feature is truely help us.
JSF is really a good framework and this feature is truely help us.
Monday, July 06, 2009
Ubuntu下如何安装Cisco VPN client - Rainman的专栏 - CSDN博客
This is a installation guide for VPN on Ubuntu.
Ubuntu下如何安装Cisco VPN client - Rainman的专栏 - CSDN博客: "Ubuntu下如何安装Cisco VPN client"
我的环境是Ubuntu 8.04, VPN Client的版本是vpnclient-linux-x86_64-4.8.01.0640-k9。
1. 下载Cisco VPN client 的压缩包vpnclient-linux-x86_64-4.8.01.0640-k9.tar.gz, 可以直接在google输入这个文件名下载。
2. 下载以后打开命令窗口执行 tar zxvf vpnclient-linux-x86_64-4.8.01.0640-k9.tar.gz解压,目录下会出现vpnclient的文件夹。
3. 下载vpnclient的patch文件, 对应这个版本的patch是vpnclient-linux-2.6.24.diff,用其他的版本应该不会成功。这个文件也可以直接在google输入文件名下载。
4. 把下载下来的vpnclient-linux-2.6.24.diff放到刚才解压的vpnclient文件夹内。
5. 把目录切换到vpnclient文件夹下。
6. 执行$ patch < vpnclient-linux-2.6.24-final.diff
7. 执行$ sudo ./vpn_install 根据提示选择安装的路径或者直接按回车按照默认路径安装
8. 执行 sudo /etc/init.d/vpnclient_init start 输入密码,如果提示Starting /opt/cisco-vpnclient/bin/vpnclient: Done就表示安装成功了。
9. 把你的pcf文件放到etc/opt/cisco-vpnclient/Profiles/ 文件夹下,比如是mypcf.pcf。
10. 执行$vpnclient connect mypcf按照提示输入你的用户名密码等等就可以开始vpn之旅了。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/jinhuiyu/archive/2009/01/18/3821246.aspx
Ubuntu下如何安装Cisco VPN client - Rainman的专栏 - CSDN博客: "Ubuntu下如何安装Cisco VPN client"
我的环境是Ubuntu 8.04, VPN Client的版本是vpnclient-linux-x86_64-4.8.01.0640-k9。
1. 下载Cisco VPN client 的压缩包vpnclient-linux-x86_64-4.8.01.0640-k9.tar.gz, 可以直接在google输入这个文件名下载。
2. 下载以后打开命令窗口执行 tar zxvf vpnclient-linux-x86_64-4.8.01.0640-k9.tar.gz解压,目录下会出现vpnclient的文件夹。
3. 下载vpnclient的patch文件, 对应这个版本的patch是vpnclient-linux-2.6.24.diff,用其他的版本应该不会成功。这个文件也可以直接在google输入文件名下载。
4. 把下载下来的vpnclient-linux-2.6.24.diff放到刚才解压的vpnclient文件夹内。
5. 把目录切换到vpnclient文件夹下。
6. 执行$ patch < vpnclient-linux-2.6.24-final.diff
7. 执行$ sudo ./vpn_install 根据提示选择安装的路径或者直接按回车按照默认路径安装
8. 执行 sudo /etc/init.d/vpnclient_init start 输入密码,如果提示Starting /opt/cisco-vpnclient/bin/vpnclient: Done就表示安装成功了。
9. 把你的pcf文件放到etc/opt/cisco-vpnclient/Profiles/ 文件夹下,比如是mypcf.pcf。
10. 执行$vpnclient connect mypcf按照提示输入你的用户名密码等等就可以开始vpn之旅了。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/jinhuiyu/archive/2009/01/18/3821246.aspx
Wednesday, May 20, 2009
Thursday, April 02, 2009
OSGi and Spring: Part 2: Build and deploy OSGi as Spring bundles using Felix
OSGi and Spring: Part 2: Build and deploy OSGi as Spring bundles using Felix: "OSGi and Spring: Part 2: Build and deploy OSGi as Spring bundles using Felix"
OSGi and Spring, Part 1: Build and deploy OSGi bundles using Apache Felix
OSGi and Spring, Part 1: Build and deploy OSGi bundles using Apache Felix: "OSGi and Spring, Part 1: Build and deploy OSGi bundles using Apache Felix"
Tuesday, March 17, 2009
Understanding Java's "Perm Gen" (MaxPermSize, heap space, etc.)
(http://mark.kolich.com/2009/01/understanding-javas-perm-gen-maxpermsize-heap-space-etc.html)
During my travels at work, I've come across a few interesting memory management issues in Java. My team has deployed several large web-applications in a single instance of Apache Tomcat. The Linux box running these applications only has about 2GB of physical memory available. Once the apps are deployed, about 1.8 GB of the memory is consumed by Java alone. Clearly, we need to improve our memory management a bit.
However, I took a few minutes to do some digging on Java's Permanent Generation (Perm Gen) and how it relates to the Java heap. Here are some distilled notes from my research that you may find useful when debugging memory management issues in Java ...
JVM arg -Xmx defines the maximum heap size. Arg -Xms defines the initial heap size. Here is an example showing how you use these JVM arguments:
-Xmx1638m -Xms512m
In Tomcat, these settings would go in your startup.sh or init script, depending on how you start and run Tomcat. With regards to the MaxPermSize, this argument adjusts the size of the "permanent generation." As I understand it, the perm gen holds information about the "stuff" in the heap. So, the heap stores the objects and the perm gen keeps information about the "stuff" inside of it. Consequently, the larger the heap, the larger the perm gen needs to be. Here is an example showing how you use MaxPermSize:
-XX:MaxPermSize=128m
FOLLOWUP 1/30/09
Here are some additional notes on interesting/important JVM parameters:
Use the JVM options -XX:+TraceClassloading and -XX:+TraceClassUnloading to see what classes are loaded/un-loaded in real-time. If you have doubts about excessive class loading in your app; this might help you find out exactly what classes are loaded and where.
Use -XX:+UseParallelGC to tell the JVM to use multi-threaded, one thread per CPU, garbage collection. This might improve GC performance since the default garbage collector is single-threaded. Define the number of GC threads to use with the -XX:ParallelGCThreads={no of threads} option.
Never call System.gc(). The application doesn't know the best time to garbage-collect, only the JVM really does.
The JVM option -XX:+AggressiveHeap inspects the machine resources (size of memory and number of processors) and attempts to set various heap and memory parameters to be optimal for long-running, memory allocation-intensive jobs.
TrackBack URL: http://mark.kolich.com/mt-tb.cgi/96
During my travels at work, I've come across a few interesting memory management issues in Java. My team has deployed several large web-applications in a single instance of Apache Tomcat. The Linux box running these applications only has about 2GB of physical memory available. Once the apps are deployed, about 1.8 GB of the memory is consumed by Java alone. Clearly, we need to improve our memory management a bit.
However, I took a few minutes to do some digging on Java's Permanent Generation (Perm Gen) and how it relates to the Java heap. Here are some distilled notes from my research that you may find useful when debugging memory management issues in Java ...
JVM arg -Xmx defines the maximum heap size. Arg -Xms defines the initial heap size. Here is an example showing how you use these JVM arguments:
-Xmx1638m -Xms512m
In Tomcat, these settings would go in your startup.sh or init script, depending on how you start and run Tomcat. With regards to the MaxPermSize, this argument adjusts the size of the "permanent generation." As I understand it, the perm gen holds information about the "stuff" in the heap. So, the heap stores the objects and the perm gen keeps information about the "stuff" inside of it. Consequently, the larger the heap, the larger the perm gen needs to be. Here is an example showing how you use MaxPermSize:
-XX:MaxPermSize=128m
FOLLOWUP 1/30/09
Here are some additional notes on interesting/important JVM parameters:
Use the JVM options -XX:+TraceClassloading and -XX:+TraceClassUnloading to see what classes are loaded/un-loaded in real-time. If you have doubts about excessive class loading in your app; this might help you find out exactly what classes are loaded and where.
Use -XX:+UseParallelGC to tell the JVM to use multi-threaded, one thread per CPU, garbage collection. This might improve GC performance since the default garbage collector is single-threaded. Define the number of GC threads to use with the -XX:ParallelGCThreads={no of threads} option.
Never call System.gc(). The application doesn't know the best time to garbage-collect, only the JVM really does.
The JVM option -XX:+AggressiveHeap inspects the machine resources (size of memory and number of processors) and attempts to set various heap and memory parameters to be optimal for long-running, memory allocation-intensive jobs.
TrackBack URL: http://mark.kolich.com/mt-tb.cgi/96
MaxPermSize and how it relates to the overall heap
(Got from Google page cache. Lost the Author)
MaxPermSize and how it relates to the overall heap
Many people have asked if the MaxPermSize value is a part of the overall -Xmx heap setting or additional to it. There is a GC document on the Sun website which is causing some confusion due to a somewhat vague explanation and an errant diagram. The more I look at this document, the more I think the original author has made a subtle mistake in describing -Xmx as it relates to the PermSize and MaxPermSize.
First, a quick definition of the "permanent generation".
"The permanent generation is used to hold reflective data of the VM itself such as class objects and method objects. These reflective objects are allocated directly into the permanent generation, and it is sized independently from the other generations." [ref]
Yes, PermSize is additional to the -Xmx value set by the user on the JVM options. But MaxPermSize allows for the JVM to be able to grow the PermSize to the amount specified. Initially when the VM is loaded, the MaxPermSize will still be the default value (32mb for -client and 64mb for -server) but will not actually take up that amount until it is needed. On the other hand, if you were to set BOTH PermSize and MaxPermSize to 256mb, you would notice that the overall heap has increased by 256mb additional to the -Xmx setting.
So for example, if you set your -Xmx to 256m and your -MaxPermSize to 256m, you could check with the Solaris 'pmap' command how much memory the resulting process is taking up.
i.e.,
$ uname -a
SunOS devnull 5.8 Generic_108528-27 sun4u sparc
SUNW,UltraSPARC-IIi-cEngine
$ java -version
java version "1.3.1_02"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.3.1_02-b02)
Java HotSpot(TM) Client VM (build 1.3.1_02-b02, mixed mode)
---------------------------------------------
$ java -Xms256m -Xmx256m -XX:MaxPermSize=256m Hello &
$ pmap 6432
6432: /usr/java1.3.1/bin/../bin/sparc/native_threads/java -Xms256m -Xmx256m
total 288416K
---------------------------------------------
Notice above that the overall heap is not 256m+256m yet? Why? We did not specify PermSize yet, only MaxPermSize.
---------------------------------------------
$ java -Xms256m -Xmx256m -XX:PermSize=256m -XX:MaxPermSize=256m Hello &
$ pmap 6472
6472: /usr/java1.3.1/bin/../bin/sparc/native_threads/java -Xms256m -Xmx256m
total 550544K
---------------------------------------------
Now we see the overall heap grow, -Xmx+PermSize. This shows conclusive proof that PermSize and MaxPermSize are additional to the -Xmx setting.
MaxPermSize and how it relates to the overall heap
Many people have asked if the MaxPermSize value is a part of the overall -Xmx heap setting or additional to it. There is a GC document on the Sun website which is causing some confusion due to a somewhat vague explanation and an errant diagram. The more I look at this document, the more I think the original author has made a subtle mistake in describing -Xmx as it relates to the PermSize and MaxPermSize.
{kind=link}
First, a quick definition of the "permanent generation".
"The permanent generation is used to hold reflective data of the VM itself such as class objects and method objects. These reflective objects are allocated directly into the permanent generation, and it is sized independently from the other generations." [ref]
Yes, PermSize is additional to the -Xmx value set by the user on the JVM options. But MaxPermSize allows for the JVM to be able to grow the PermSize to the amount specified. Initially when the VM is loaded, the MaxPermSize will still be the default value (32mb for -client and 64mb for -server) but will not actually take up that amount until it is needed. On the other hand, if you were to set BOTH PermSize and MaxPermSize to 256mb, you would notice that the overall heap has increased by 256mb additional to the -Xmx setting.
So for example, if you set your -Xmx to 256m and your -MaxPermSize to 256m, you could check with the Solaris 'pmap' command how much memory the resulting process is taking up.
i.e.,
$ uname -a
SunOS devnull 5.8 Generic_108528-27 sun4u sparc
SUNW,UltraSPARC-IIi-cEngine
$ java -version
java version "1.3.1_02"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.3.1_02-b02)
Java HotSpot(TM) Client VM (build 1.3.1_02-b02, mixed mode)
---------------------------------------------
$ java -Xms256m -Xmx256m -XX:MaxPermSize=256m Hello &
$ pmap 6432
6432: /usr/java1.3.1/bin/../bin/sparc/native_threads/java -Xms256m -Xmx256m
total 288416K
---------------------------------------------
Notice above that the overall heap is not 256m+256m yet? Why? We did not specify PermSize yet, only MaxPermSize.
---------------------------------------------
$ java -Xms256m -Xmx256m -XX:PermSize=256m -XX:MaxPermSize=256m Hello &
$ pmap 6472
6472: /usr/java1.3.1/bin/../bin/sparc/native_threads/java -Xms256m -Xmx256m
total 550544K
---------------------------------------------
Now we see the overall heap grow, -Xmx+PermSize. This shows conclusive proof that PermSize and MaxPermSize are additional to the -Xmx setting.